CONCLUSION
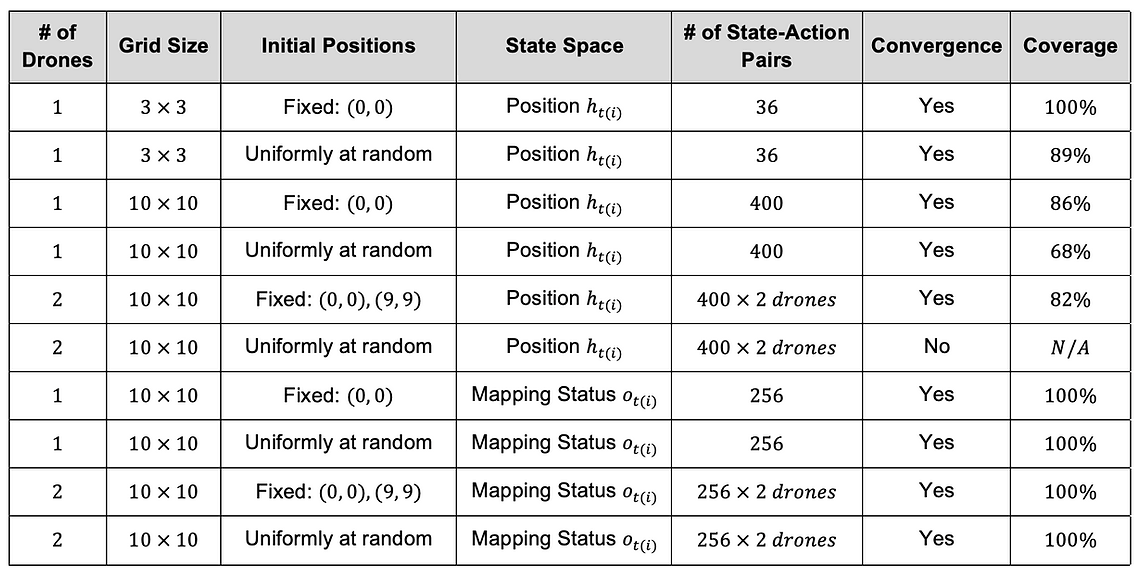
In this research, we modeled the deployment of autonomous drone swarms to post-disaster damage assessment as the mapping task. We compared two different state spaces and found that using drones’ observations of the mapping status within their FOV as a state is a better solution in terms of coverage and scalability. This result implies that we can develop a decentralized control version; each drone takes action only consuming a local observation without communicating with a central controller.
In damage assessment, a decentralized control has two advantages. First, a centralized control system is challenging to scale up to a large number of drones because of its fragility to a single point of failures and communication outages. Second, drones can regulate themselves without Global Positioning System (GPS).
In such cases where buildings surround the disaster area (e.g., downtown) or we need to inspect indoors (e.g., subway stations), a GPS signal from satellites may become too weak for drones to navigate the environment accurately. Therefore, the decentralized control using drones’ local observation as a state is a promising solution for scalable damage assessment.
We observed that the Multi-Agent Independent Q-learning had the limitation to reduce redundant actions. In damage assessment, redundancy may contribute to increasing the confidence of damage information in a particular spot. However, especially for a primary damage assessment immediately after a disaster, speed to map a disaster area thoroughly is critical. We hypothesize that incorporating GNNs as an RL policy network could minimize redundancy and achieve decentralized control.
We can evaluate its performance by how efficiently the drones map the environment (e.g., time steps to reach 95% coverage). The performance of our Multi-Agent Independent Q-learning algorithm will be a baseline for such future work. Also, we assume Deep Q-Networks could be another baseline.